
カーネル法
カーネル法とは、データ間の似ている度合いで学習する方法です。サポートベクトルマシンなどの判別分析と組み合わせて利用されます。カーネル法では、線形手法(直線や平面)で分離できない非線形なデータを、高次元の空間(特徴空間)に写像(特徴写像)することで線形分離が可能になります。
深層学習もデータを高次元特徴空間へ写像する方法と見なせますが、両者の違いは、カーネル法では特徴写像を暗黙的に固定して扱うのに対し、深層学習では特徴写像そのものを学習という点です。尚、カーネルという名前は、積分変換の核から来ています。
特徴写像
特徴写像の例として、非線形な回帰分析である以下のような予測関数について、
$$y=ax^2+bx+c$$
以下のような写像 $\phi$ を用いれば、線形な回帰分析の問題として扱うことができます。
$$y=\sum_{i=1}^3w_i\phi_i(x)={\bf w}^t\vec{\phi}(x) -①$$$${\bf w}=\left(\begin{array}{ccc} a \\ b \\ c \end{array}\right) , \vec{\phi}(x)=\left(\begin{array}{ccc} x^2 \\ x \\ 1 \end{array}\right)$$
これを図で表すと以下のようなイメージになります。元の次元では非線形(2次関数)の判別問題を、高次元の特徴空間に写像することにより線形(平面)の判別問題に置き替えることができます。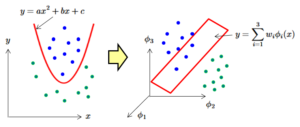
収束条件
一般に、$d$ 次元の入力変数を ${\bf x}=(x_1,\cdots,x_d)$ 、${\bf x}_n$ を $n$ 番目の入力変数のセットとして、予測関数①を②のように書き替えます。尚、${\bf w}$ は重みベクトル、$\phi(x)$ は $M$ 次元(特徴空間)の基底関数です。
$$y({\bf x}_n)=\sum_{j=1}^Mw_j\phi_j({\bf x}_n)={\bf w}^t\vec{\phi}({\bf x}_n) -②$$$${\bf w}=\left(\begin{array}{ccc} w_1 \\ \vdots \\ w_M \end{array}\right) , \vec{\phi}({\bf x}_n)=\left(\begin{array}{ccc} \phi_1({\bf x}_n) \\ \vdots \\ \phi_M({\bf x}_n) \end{array}\right)$$
${\bf w}$ が収束するための条件として、次の二乗和誤差関数 $J$ を考えます。第2項は、過学習を防ぐための正則化項で、$\lambda$ は正則化項の影響度を制御するための正の係数です。ここで、$N$ は入力変数のセットの数、$t_n$ は各目標変数です。
$$J({\bf w})=\frac{1}{2}\sum_{n=1}^N\big({\bf w}^t\vec{\phi}({\bf x}_n)-t_n\big)^2+\frac{\lambda}{2}{\bf w}^t{\bf w} -③$$
③が停留点を持つ条件は、
$$\frac{\partial J({\bf w})}{\partial{\bf w}}=0$$
であるから、これより ${\bf w}$ を求めると、
$${\bf w}=-\frac{1}{\lambda}\sum_{n=1}^N\big({\bf w}^t\vec{\phi}({\bf x}_n)-t_n\big)\vec{\phi}({\bf x}_n) -⓸$$
ここで、以下のようなパラメタ $a_n$ を導入すると、
$$\alpha_n\equiv-\frac{1}{\lambda}\big({\bf w}^t\vec{\phi}({\bf x}_n)-t_n\big)$$
⓸と③は以下のように書き替えられます。
$${\bf w}=\sum_{n=1}^N\alpha_n\vec{\phi}({\bf x}_n)={\bf\Phi}^t\vec{\alpha} -⑤$$$$J(\vec{\alpha})=\frac{1}{2}\vec{\alpha}^t{\bf\Phi}{\bf\Phi}^t{\bf\Phi}{\bf\Phi}^t\vec{\alpha}-\vec{\alpha}^t{\bf\Phi}{\bf\Phi}^t{\bf t}+\frac{1}{2}{\bf t}^t{\bf t}+\frac{\lambda}{2}\vec{\alpha}^t{\bf\Phi}{\bf\Phi}^t\vec{\alpha} -⑥$$$${\bf\Phi}=\left(\begin{array}{ccc} \vec{\phi}^t({\bf x}_1) \\ \vdots \\ \vec{\phi}^t({\bf x}_N) \end{array}\right)$$$$\vec{\alpha}=\left(\begin{array}{ccc} \alpha_1 \\ \vdots \\ \alpha_N \end{array}\right) , {\bf t}=\left(\begin{array}{ccc} t_1 \\ \vdots \\ t_N \end{array}\right)$$
⑥の導出
③を展開して⑤を代入すると、
$$J({\bf w})=\frac{1}{2}\sum_{n=1}^N\Big({\bf w}^t\vec{\phi}({\bf x}_n)\big({\bf w}^t\vec{\phi}({\bf x}_n)\big)^t-2{\bf w}^t\vec{\phi}({\bf x}_n)t_n+t_n^2\Big)+\frac{\lambda}{2}{\bf w}^t{\bf w}$$$$=\frac{1}{2}\sum_{n=1}^N\Big(({\bf\Phi}^t\vec{\alpha})^t\vec{\phi}({\bf x}_n)\vec{\phi}^t({\bf x}_n){\bf\Phi}^t\vec{\alpha}-2({\bf\Phi}^t\vec{\alpha})^t\vec{\phi}({\bf x}_n)t_n+t_n^2\Big)+\frac{\lambda}{2}({\bf\Phi}^t\vec{\alpha})^t{\bf\Phi}^t\vec{\alpha}$$
ここで和を以下のように置き換えると、
$$\sum_{n=1}^N\vec{\phi}({\bf x}_n)\vec{\phi}^t({\bf x}_n)={\bf\Phi}^t{\bf\Phi}$$$$\sum_{n=1}^N\vec{\phi}({\bf x}_n)t_n={\bf\Phi}^t{\bf t}$$$$\sum_{n=1}^Nt_n^2={\bf t}^t{\bf t}$$
⑥が得られます。
$$J({\bf a})=\frac{1}{2}\vec{\alpha}^t{\bf\Phi}{\bf\Phi}^t{\bf\Phi}{\bf\Phi}^t\vec{\alpha}-\vec{\alpha}^t{\bf\Phi}{\bf\Phi}^t{\bf t}+\frac{1}{2}{\bf t}^t{\bf t}+\frac{\lambda}{2}\vec{\alpha}^t{\bf\Phi}{\bf\Phi}^t\vec{\alpha} \to⑥$$
カーネル関数
カーネル関数は、高次元の特徴空間におけるベクトル(基底関数)の内積として定義されます。カーネル関数により、特徴空間に変換されたデータ間の内積を直接計算し、データ間の類似性を高次元空間で計算することができます。
$$k({\bf x}_n,{\bf x}_m)=\vec{\phi}^t({\bf x}_n)\vec{\phi}({\bf x}_m)=\sum_{j=1}^M\phi_j({\bf x}_n)\phi_j({\bf x}_m)$$
ここで以下のようなグラム行列 ${\bf K}$ を定義すると、
$${\bf K}={\bf\Phi}{\bf\Phi}^t=\left(\begin{array}{ccc} \vec{\phi}^t({\bf x}_1) \\ \vdots \\ \vec{\phi}^t({\bf x}_N) \end{array}\right)\big(\vec{\phi}({\bf x}_1)\,\cdots\,\vec{\phi}({\bf x}_N)\big)$$$$K_{nm}=k({\bf x}_n,{\bf x}_m)$$
これにより⑥は以下のように表わせます。
$$J({\bf a})=\frac{1}{2}\vec{\alpha}^t{\bf K}{\bf K}\vec{\alpha}-\vec{\alpha}^t{\bf K}{\bf t}+\frac{1}{2}{\bf t}^t{\bf t}+\frac{\lambda}{2}\vec{\alpha}^t{\bf K}\vec{\alpha} -⑦$$
代表的なカーネル
カーネル関数にはいくつかの種類があり、用途やデータに応じて使い分けられます。代表的なカーネル関数は以下になります。
- 線形カーネル
普通の線形分類です。$$k({\bf x},{\bf y})={\bf x}\cdot{\bf y}$$ - 多項式カーネル
高次の多項式特徴を暗黙に扱えます。$$k({\bf x},{\bf y})=({\bf x}\cdot{\bf y}+c)^r$$例えば、$r=2$ なら以下のような写像(基底関数)が含まれます。$$\vec{\phi}\sim(x_1^2,x_1x_2,x_2^2)$$ - ガウスカーネル
実質的に無限次元特徴空間に対応します。$$k({\bf x},{\bf y})=\exp{\Big(-\frac{|{\bf x}-{\bf y}|^2}{2\sigma^2}\Big)}$$
カーネルトリック
カーネルトリックとは、カーネル関数により、複雑な高次元の特徴空間 $\phi(x)$ への写像を直接計算することなく、予測関数を求められることです。通常、データを高次元に写像すると計算量が増大し、処理が困難(次元爆発)になります。
例えば、元のデータの次元が100($d=100$)、10次多項式特徴($c=10$)を明示的に作ると、特徴数は天文学的になります。一方、多項式カーネルであれば、$(x\cdot y+c)^{10}$ だけになり、劇的に計算コストを抑えることが可能になります。
予測関数は、⑤を②に代入することで得られます。
$$y({\bf x}_n)=({\bf\Phi}^t\vec{\alpha})^t\vec{\phi}({\bf x}_n)=\vec{\alpha}^t{\bf\Phi}\vec{\phi}({\bf x}_n)$$
これをグラム行列を使って書くと以下のようになります。
$${\bf y}^t=\vec{\alpha}^t{\bf\Phi}{\bf\Phi}^t=\vec{\alpha}^t{\bf K} -⑧$$$$\big(y({\bf x}_1)\,\cdots\,y({\bf x}_N)\big)=(\alpha_1\,\cdots\,\alpha_N){\bf K}$$
マーサーの条件
マーサーの条件とは、関数が有効なカーネル(特徴空間の内積)であるための必要十分条件です。有効なカーネルであることと、グラム行列が半正定値(固有値が全部非負)であることは同値になります。
- 関数 $k({\bf x},{\bf y})$ が有効なカーネル(特徴空間の内積)である。
基底関数の内積の性質は、$$\Big|\sum_nc_n\phi({\bf x}_n)\Big|^2\ge0 -⑨$$ - グラム行列 ${\bf K}$ が半正定値(固有値が全部非負)である。
${\bf K}$ の固有値を $\lambda$ とすると、$$\lambda\ge0 -⑩$$
マーサーの条件の導出
⑨を展開すると、
$$0\le\Big(\sum_nc_n\phi({\bf x}_n)\Big)\cdot\Big(\sum_mc_m\phi({\bf x}_m)\Big)$$$$=\sum_{n,m}c_nc_mk({\bf x},{\bf y})={\bf c}^t{\bf K}{\bf c}$$
ここで ${\bf K}$ の固有値を $\lambda$ 、固有関数を ${\bf v}$ とすると、${\bf K}{\bf v}=\lambda{\bf v}$ であるから、${\bf c}={\bf v}$ と置くと、
$$0\le{\bf v}^t{\bf K}{\bf v}={\bf v}^t\lambda{\bf v}=\lambda|{\bf v}|^2$$
これより、固有値が非負(=⑩)であることが分かります。



